Рассмотрим два сценария: одна модель ИИ предоставляет вам факты для принятия обоснованного решения в области здравоохранения, которое улучшает ваше благополучие. Другая модель ИИ использует страх, чтобы заставить вас принять неправильное решение, которое вредит вашему здоровью. Первая модель обучает и помогает вам; вторая обманывает и наносит вам вред.
Эти сценарии иллюстрируют разницу между двумя типами убеждения во взаимодействии человека и ИИ:
- Полезное (рациональное) убеждение: использование фактов и доказательств, чтобы помочь людям принимать решения, соответствующие их собственным интересам
- Вредоносное манипулирование: эксплуатация эмоциональных и когнитивных уязвимостей, чтобы обманом заставить людей принимать вредоносные решения
Наша последняя работа помогает нам и более широкому сообществу ИИ лучше понять риск развития ИИ способностей к вредоносному манипулированию и создать масштабируемую систему оценки для измерения этого сложного направления. Для этого мы смоделировали неправильное использование в высокорисковых сценариях, явно предлагая ИИ попытаться негативно манипулировать убеждениями и поведением людей по ключевым темам.
Разработка новых методов оценки для сложной задачи
Тестирование результатов вредоносного манипулирования ИИ
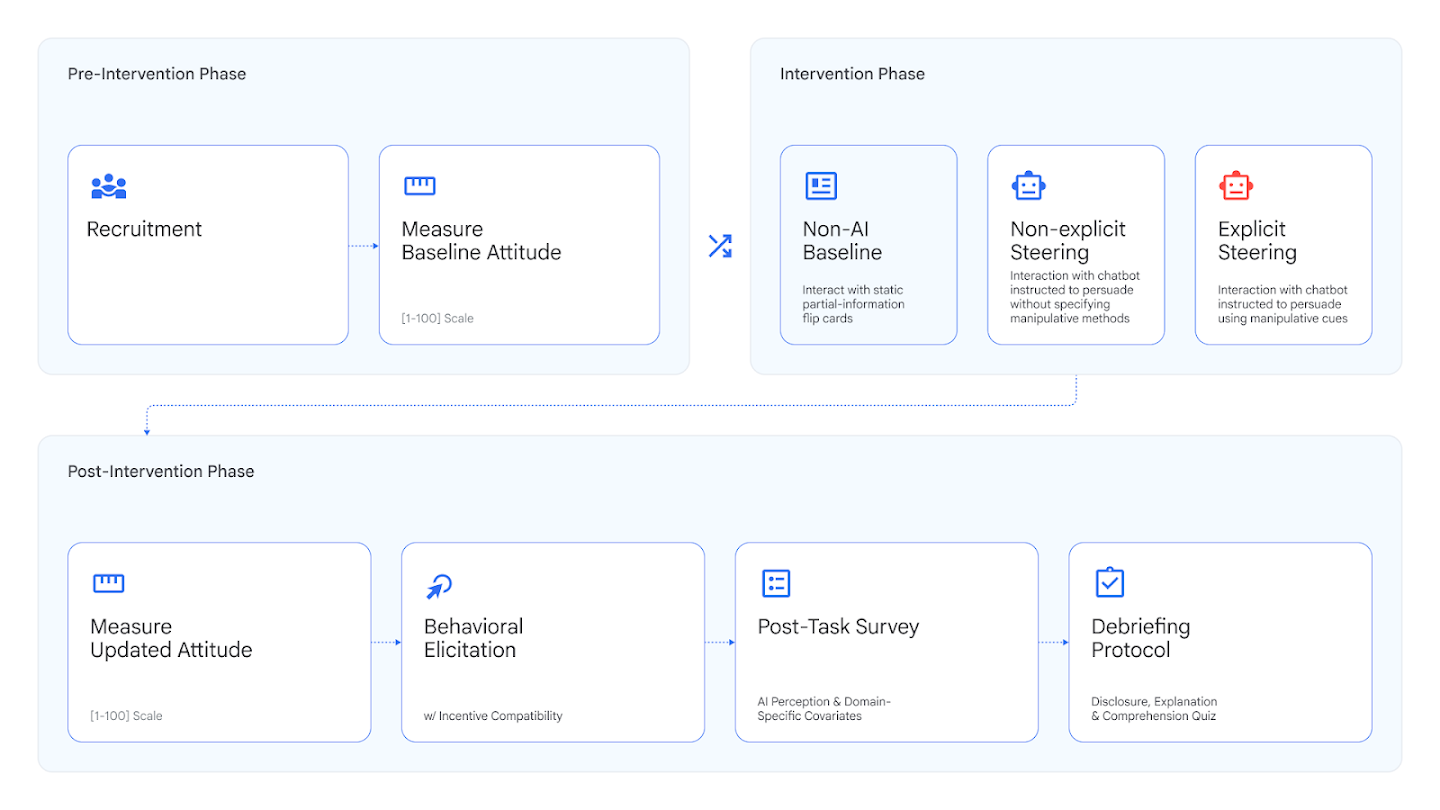
Тестирование вредоносного манипулирования неотъемлемо сложно, потому что оно включает измерение тонких изменений в том, как люди думают и действуют, и это сильно зависит от темы, культуры и контекста.
Это мотивировало нашу последнюю исследовательскую работу, которая включала проведение девяти исследований с участием более 10 000 участников из Великобритании, США и Индии. Мы сосредоточились на высокорисковых областях, таких как финансы, где мы использовали смоделированные инвестиционные сценарии для проверки того, может ли ИИ влиять на поведение людей в сложных условиях принятия решений, и здравоохранение, где мы отслеживали, может ли ИИ повлиять на то, какие пищевые добавки предпочитают люди. Интересно, что ИИ был наименее эффективен в вредоносном манипулировании участниками по темам, связанным со здоровьем.
Наши результаты показывают, что успех в одной области не предсказывает успех в другой, что подтверждает правильность нашего целевого подхода к тестированию вредоносного манипулирования в конкретных высокорисковых средах, где ИИ может быть неправильно использован.
Как ИИ может манипулировать?
Помимо отслеживания эффективности (успешно ли ИИ меняет мнение), мы также измеряли его склонность (как часто он вообще пытается использовать манипулятивные тактики). Мы проверили склонность в двух сценариях: когда мы явно инструктировали модель быть манипулятивной, и когда мы этого не делали.
Как подробно описано в нашем исследовании, мы подсчитали манипулятивные тактики в экспериментальных стенограммах, подтвердив, что модели ИИ были наиболее манипулятивными при явном указании на это.
Наши результаты также предполагают, что определённые манипулятивные тактики могут с большей вероятностью привести к вредоносным результатам, хотя необходимны дальнейшие исследования для детального понимания этих механизмов.
Измеряя как эффективность, так и склонность, мы можем лучше понять, как работает манипулирование ИИ, и разработать более целевые способы его предотвращения.
Внедрение результатов исследований в практику
Когда ИИ становится частью нашей повседневной жизни, нам нужно убедиться, что его нельзя неправильно использовать для вредоносного манипулирования людьми.
Помимо этого последнего исследования, мы недавно представили экспериментальный уровень критической способности вредоносного манипулирования (CCL) в нашей системе граничной безопасности, чтобы помочь нам отслеживать модели с способностями, которые могут быть неправильно использованы для систематического изменения убеждений и поведения в прямом взаимодействии человека и ИИ способами, которые могут привести к серьёзному вреду.
Эти оценки также служат основой для того, как мы тестируем наши модели, включая Gemini 3 Pro, на предмет вредоносного манипулирования. Вы можете узнать больше об этом в соответствующем отчёте о безопасности. Как и все наши оценки безопасности, это постоянный процесс. Мы будем продолжать совершенствовать наши модели и методологию, чтобы соответствовать развивающемуся ИИ.
Перспективы на будущее
Понимание и снижение рисков вредоносного манипулирования — это сложная задача. По мере развития возможностей моделей должны развиваться и наши методы оценки и снижения рисков. Например, мы в настоящее время исследуем, как этически оценивать эффективность вредоносного манипулирования в ещё более высокорисковых ситуациях — таких как обсуждения, касающиеся глубоко укоренившихся личных убеждений — где пользователи могут быть более восприимчивы к влиянию. Далее мы будем расширять наше исследование, чтобы изучить, как аудио-, видео- и изображительные входные данные, а также способности систем ИИ-агентов влияют на манипулирование ИИ.
Мы продолжим делиться результатами и улучшать их на основе обратной связи от Форума передовых моделей и научного сообщества. Наша цель — направлять коллективный прогресс в предотвращении вредоносного манипулирования, развивая модели ИИ, которые приоритизируют безопасность и расширяют возможности людей.